|
To understand the wildness of samples, we would choose
thousands of samples, calculate an x-bar for each, and display the x-bars
in a histogram. This histogram represents a sampling distribution and when
we look at it we see something truly amazing. Sampling distributions tend
to be far less variable or wild than the populations they are drawn from
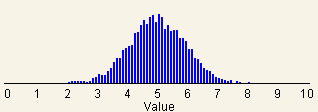
(See Fig. 1A, 1B, 1C and 1D.) They also have essentially the same mean as
the population.
Sampling distributions drawn from a uniformly
distributed population start to look like normal distributions even with a
sample size as small as 2 (see Fig. 1B). If the sample size is large
enough they form nearly perfect normal distributions (see Fig. 1C). Make
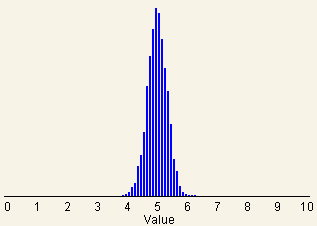
the sample size larger and the variability of the sampling distribution
drops even more. The sampling distribution starts looking spike-like
because a normal distribution with very little variability (in other words
a small standard deviation) is so narrow that it looks spike-like (see
Fig. 1D).
This may not seem Earth shattering but it’s really quite
profound. Anytime we know data follows a normal distribution, we
immediately have a lot more confidence that we can predict how the data
will behave.
The situation is similar to hiring Mary Jane, who has a
master’s degree in computer science versus Jim Bob who says he can
compute. Jim Bob may turn out to be better at creating software. However,
by knowing that Mary Jane has a master’s degree we feel a lot more
confident in our ability to predict her programming capability.
It would be highly annoying if we had to generate an
entire sampling distribution every time we want to be sure that our
statistic based on a sample really is less wild than the data points in
the population. Fortunately, we know this ahead of time, thanks to the
(arguably) second most profound principle in all of statistics, the
central limit theorem (the law of large numbers being the first).
The central limit theorem tells us that a sampling
distribution always has significantly less wildness or variability, as
measured by standard deviation, than the population it’s drawn from.
Additionally, the sampling distribution will look more and more like
normal distribution as the sample size is increased, even when the
population itself is not normally distributed!
Although the central limit theorem works well regardless
of the population's distribution, with really strange distributions, it
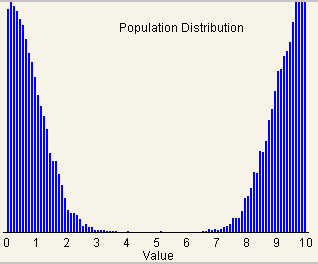
takes a lot more than a sample size of two to do so. For example, bimodal
distribution (see Fig. 2A) will not look normally distributed with only a
sample size of two. The sampling distribution in this case will have a
third high narrow peak in the center with a lower wider peak on either
side (see Fig. 2B). Increasing the sample size by one adds another peak
(see Fig. 2C). Eventually, with a large enough sample size, there are so
many peaks that they run together and the sampling distribution starts to
look like a typical normal distribution.
The applet included in this article illustrates this
nicely. It contains a highly skewed as well as a bimodal population. All
of the populations in it are created using various random number
generators that more closely simulate what real populations are like than
simply generating populations from smooth density curve equations.
If we use standard deviation as a measurement of
wildness the standard deviation of a sampling distribution (sometimes
called the standard error) can be predicted from the population standard
deviation as follows:
|
|
|
|
ss |
=
sp / (n)^0.5
|
equation (1) |
|
|
|
|
|
|
| |
where: |
| |
|
ss
= standard deviation of sampling
distribution or standard error |
| |
|
sp
= standard deviation of the population |
| |
|
n = sample size |
|
|
|
When we look at equation (1) we notice something very
profound because it’s missing. There’s no term for the size of the
population. This means that the reduction in wildness depends only on the
sample size. In other words, a statistic based on a sample size of
say 2000 will be just as meaningful if it’s drawn from a population of
20,000,000,000 as it will be if it’s drawn from a population of 20,000.
Population size does not matter as long as it’s at least 10 times larger
than the sample.
If the central limit theorem didn’t exist, it would not
be possible to use statistics. We would be unable to reliably estimate a
parameter like the mean by using an average derived from a much smaller
sample. This would all but shut down research in the social sciences and
the evaluation of new drugs since these depend on statistics. It would
invalidate the use of polls and completely alter the nature of marketing
research not to mention politics.
Thanks to the central limit theorem, we can be sure that
a mean or x-bar based on a reasonably large randomly chosen sample will be
remarkably close to the true mean of the population. If we need more
certainty we need only increase the sample size. What’s more, it does not
matter if we are characterizing a city, state, or the entire United
States, we can use the same sample size. It will give the same level of
certainty regardless of the population size.
For further Information
Sampling
Distribution Applet: This applet can also be very helpful for
understanding sampling distributions. However, be aware that in it the
sampling distribution's vertical scale changes with the number of samples
and the sample size only goes up to 25. This hides the dramatic narrowing
effect on the sampling distribution caused by increasing sample size. The
applet provided in the above article plots population and sampling distributions on exactly the
same scales and allows sample sizes of 100, all of which make the
narrowing effect highly visible. Both applets are correct although they
look different due to differences in scales.
< Return to Contents
|